本笔记参考如下资料和笔记
预训练
为什么要预训练
预训练存在的意义:在数据(样本量)不够的时候,完成深度学习任务
- 深度学习和机器学习最主要的区别:深度学习建立在海量的样本数据上,机器学习侧重于使用统计数学的方法
预训练是什么
一个发现:两个相似的任务,网络结构基本相同
以CNN为例

浅层的结构和特征基本是相同的
预训练借鉴了这种思想,使用以下两种方式来复用网络结构
- 冻结:直接服用浅层网络参数不做出改变
- 微调:改变网络结构(使用目标任务数据集训练)
至此引入预训练的概念:通过一个训练好的模型,通过改变/不改变部分参数完成另外一个任务
预训练的局限:两个任务必须要极其相似,具有足够的可复用性
Transformer与BERT的贡献:解决了上面这个复用性不足的问题
预训练的使用
Python的一些库,fairseq,transformers
统计语言模型
语言模型
语言模型的任务
- 判断某两句话哪个出现的概率大
- 完形填空
- 牛顿最主要的贡献是发现了
_______
- 牛顿最主要的贡献是发现了
统计语言模型
- 问题一的解决:用统计的方法完成语言模型的任务
(条件概率的公式)
- 问题二的解决 计算
$$ max(P(w_{next}|w_1,w_2,…w_n)) $$ 即可 使用一个词库装所有的词,遍历整个词库计算哪个概率最大(计算量巨大)
n元统计语言模型
解决了上面这个问题
方法:观察到,其实去掉几个词语不影响最后的判断
“牛顿”,“发现了”和“牛顿” ,”最主要的”,“贡献”,“是”,“发现了” 预测结果差不多
取n个次中间的几个(i元)
平滑策略
通俗的理解:为了避免出现 \( \frac{0}{0} \) 的情况(这种情况往往是因为词库里没有该词),分子分母加上处理
由于词库很大,
很多种修正方法,不一一列举
神经网络语言模型
one-hot编码
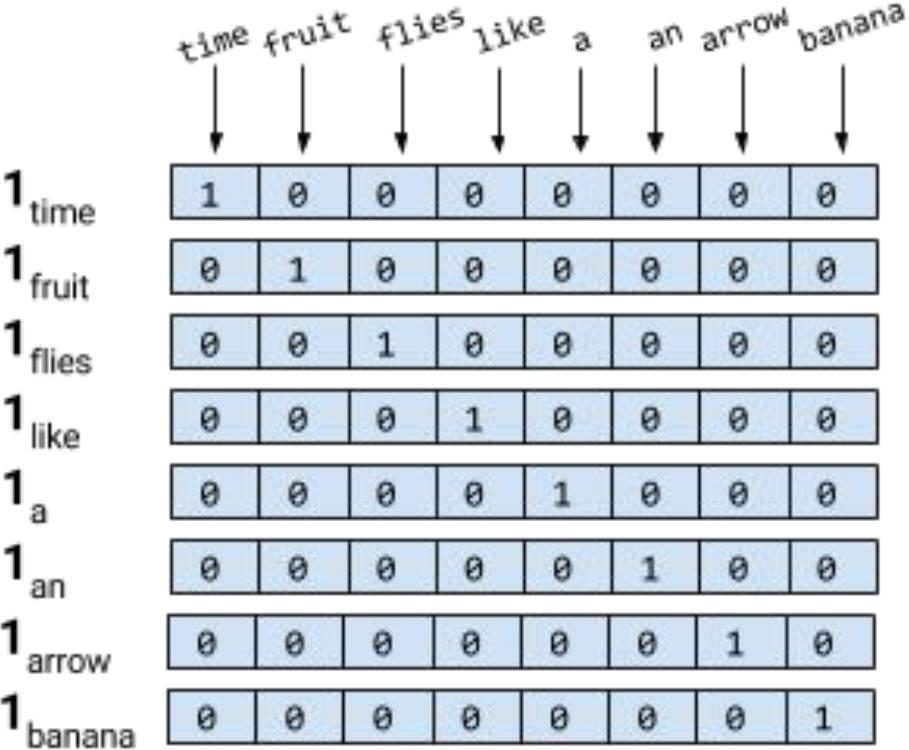
对于词典V,编码其中的单词
使用矩阵存储,只有对应标号的单词索引值为1
time->(1,1)为1,对角线呈现此规律
只需要使用n*n矩阵,就可以存储n个单词
one-hot的缺陷:在衡量单词的余弦相似度时,one-hot使两个单词间的相似度变得不显著
神经网络语言模型
使用神经网络解决语言模型的任务,以解决统计语言模型计算量大的问题
以任务二为例
假设有四个单词w1,w2,w3,w4
w1*q=c1
w2*q=c2
w3*q=c3
w4*q=c4
C=[c1,c2,c3,c4]
Wn为第n个单词的独热编码
Q为随机矩阵,C作为输入进入两层感知机网络
得到一个一维向量,维数为词典包含的单词个数
词向量
由于Q是一个随机矩阵,所以Q是可以学习的
Q矩阵训练完成之后,Wn * Q = Cn,Cn就是所谓的词向量,就是用一个向量表示一个单词
由于矩阵Q的维度可以决定词向量的维度,所以可以达到压缩的作用,同时也解决了独热编码不同词内积为0的情况
Word2Vec模型
主要作用就是把输入的词语编码,输入到后面一级的神经网络的语言模型进行预测,相当于替代了Q的作用
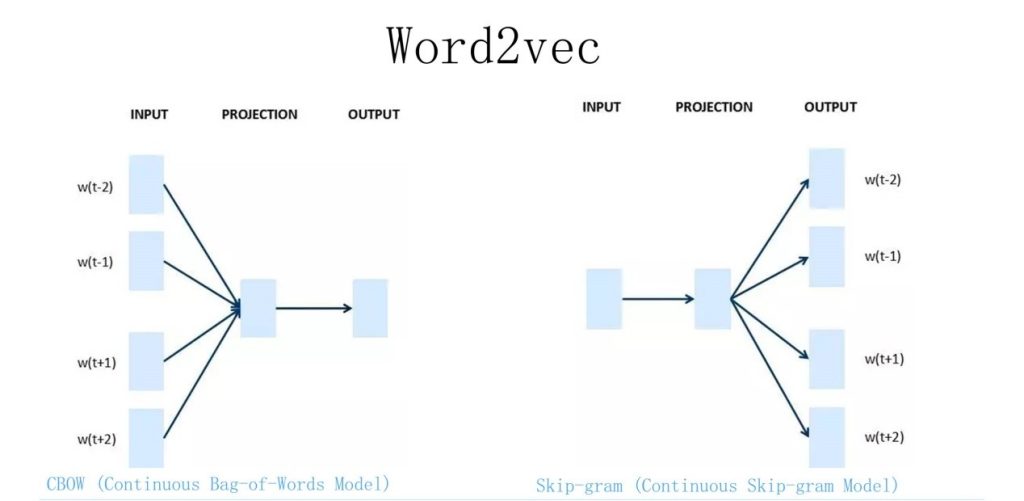
CBOW
给出一个词(待确定)的上下文,预测出这个词
Skip-gram
给出一个词,得到上下文
两者的区别,主要在于内部的结构,CBOW是一个输出,指导多个输入的Q矩阵,Skip-gram是多个输出指导一个输入的Q矩阵
缺点:所有词语的多义都被忽略了,一个独热编码只能被编码成一个值,导致词的多义无法被体现
预训练模型的下游任务改造
预训练语言模型,最简单来说其实就是这个Q矩阵来编码输入的词
相比于独热编码的一一对应,这个是一个预训练的模型,这个是最大区别
编码后的词,进入后面的前馈层处理,这部分不是预训练得到的,所谓的
ELMo模型
主要作用是解决多义词无法被编码的问题
不只是训练一个Q矩阵
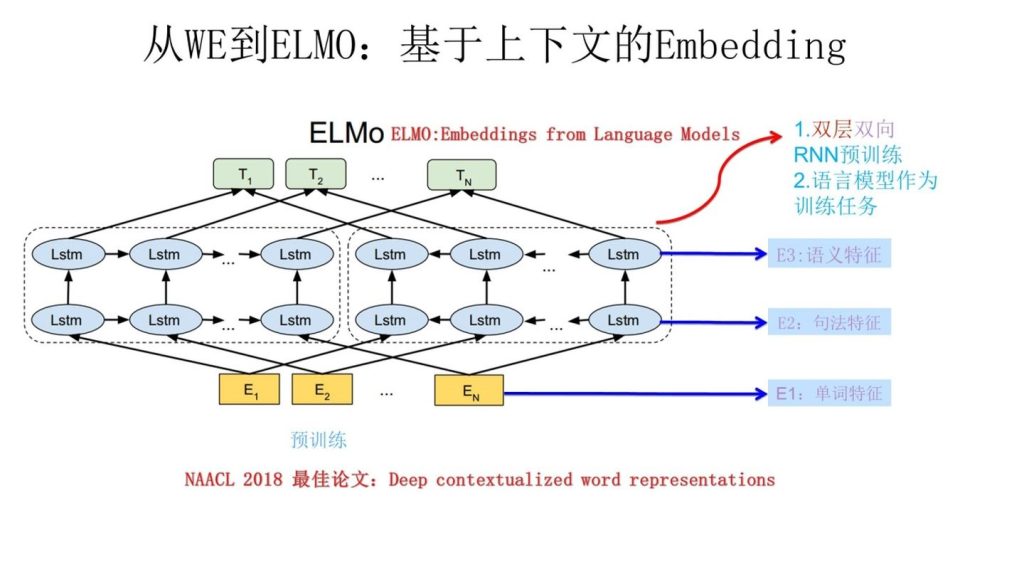
LSTM网络提供上下文信息,以E2为例,进入左边的网络,E1的LSTM给它信息,进入右边的网络,E3,E4…En给它信息
因此编码后的词向量,T1,T2…Tn具有了上下文信息,左边网络对应上文信息,右边网络对应下文信息
加上了上下文信息的词向量,在进行编码的时候就不会出现多义无法体现的问题
Attention
注意力机制:解决面对大量数据的时候,如何去利用更有用的数据,减少使用不重要的数据
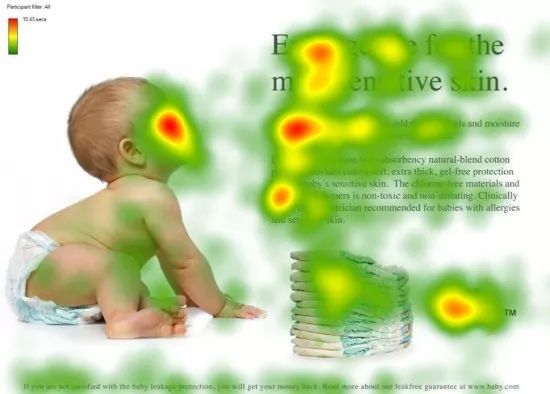
以视觉为例,人类对图片的关注焦点如上图,会把焦点聚焦在重要的事物上
- Q:查询对象(看图的人)
- V:被查询对象(图片)
衡量注意力,重要性,转化为Q和K的相似度来衡量
Q和K相当于从两个角度的特征,Q代表从观察者(查询者)的角度来看,我需要直观地关注什么信息,K代表从图片(被查询者)的角度来看,图片主观上能提供什么信息,因此这两者的相似度就可以理解成供需的匹配度
在Transformer和BERT中,使用两个矩阵的点乘来计算相似度,计算完相似度后,使用Softmax归一化来衡量相似度(得到一个重要性的百分比)
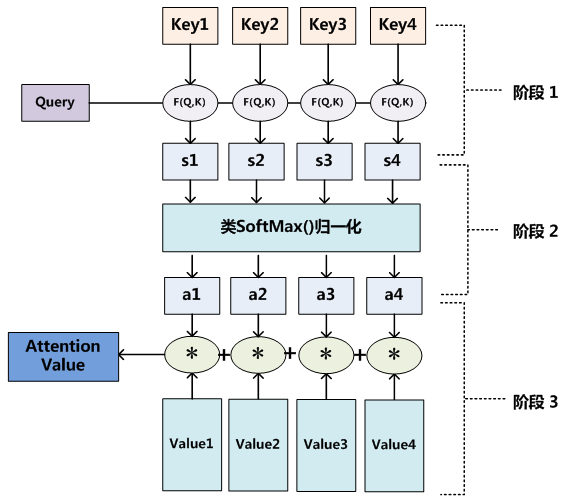
归一化后的a在与V作内积,就可以得到具有信息的V,这个V含有了观察者想要观察的更重要的信息
一般来说,K=V(Transformer),但是K和V一定要要有关联,这样才能生成指导生成新V的a
Self-Attention
交叉注意力机制:K=V,Q自定义
Self-Attention:核心就是 K=V=Q(近似相等),来源于同一个X,从下图可以看出三者是同源的,来自于同一个X,只是线性变换的方式不一样
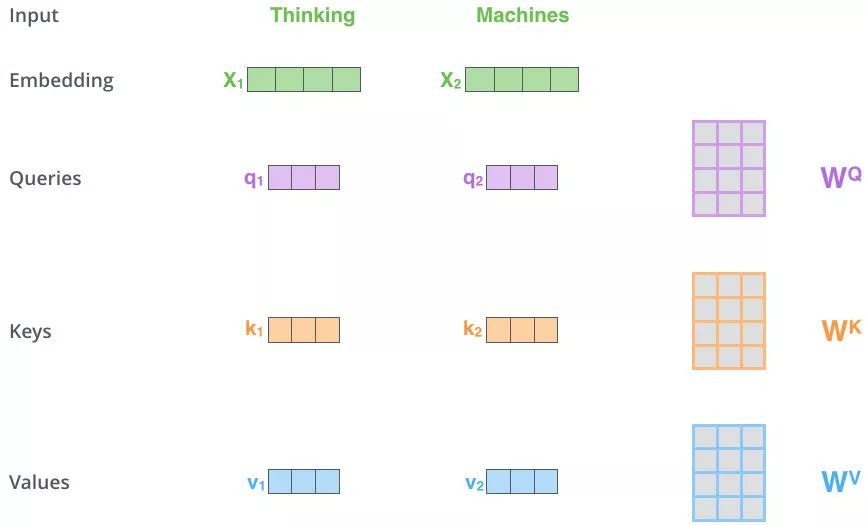
接下来就和注意力机制进行一模一样的操作
最后得到的Values,和上一步不同,没有主观地进行注意力的生成。由于此时的QKV都是一个X生成的,因此包含自己的信息最多,同时也包含了上下文的信息
- 这里的X1,X2就可以理解成上下文的两个单词
RNN,LSTM以及Self-Attention
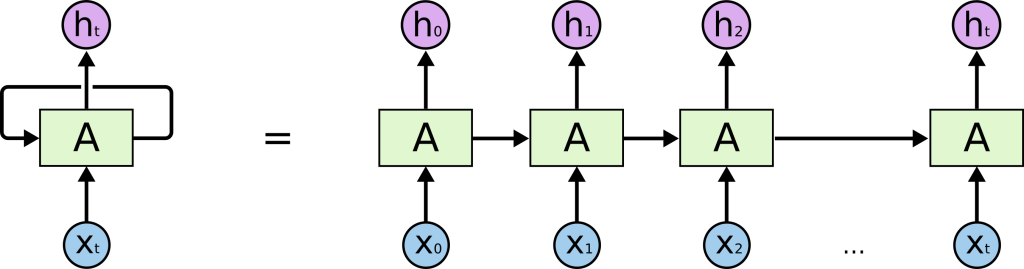
RNN的问题:对于长序列,前文的信息传到后文时容易消失
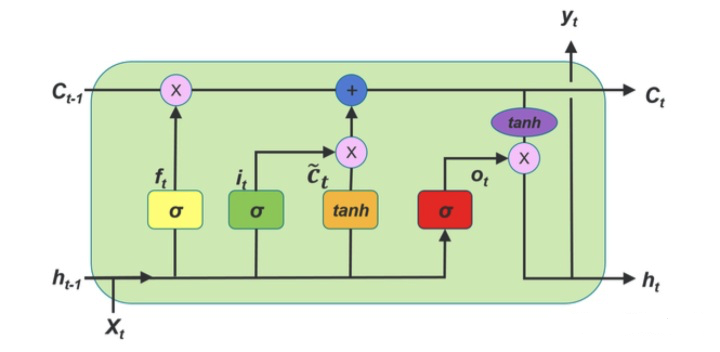
LSTM通过各种门的都解决了长序列的问题
两者都有一个问题:无法做并行上的计算
Attention:可以解决这两个问题
原因:
- 由于做的是每个词的词向量编码,因此每个词都可以获取整个上下文信息
- 后面词的attention计算,不受前面词计算结果的影响
Masked Self-Attention
在生成模型(GPT)的任务中,由于词是一个一个生成的,理论上第一个单词并不知道后面的词句信息
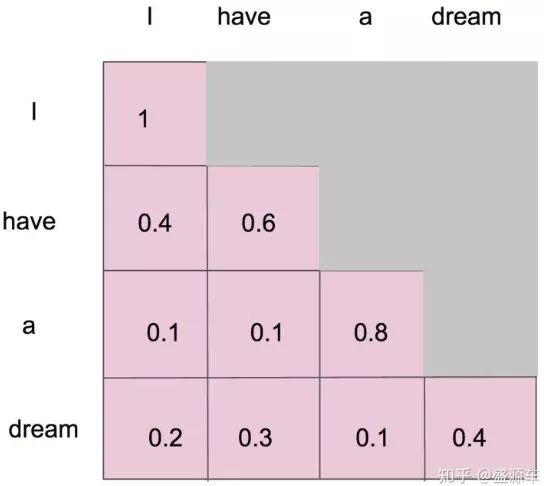
如图,前面的单词不计算全部的注意力,只有最后一个单词的计算才能计算出所有的注意力信息
Muiti-Head Self-Attention
多头自注意力,一般使用8个注意力单元
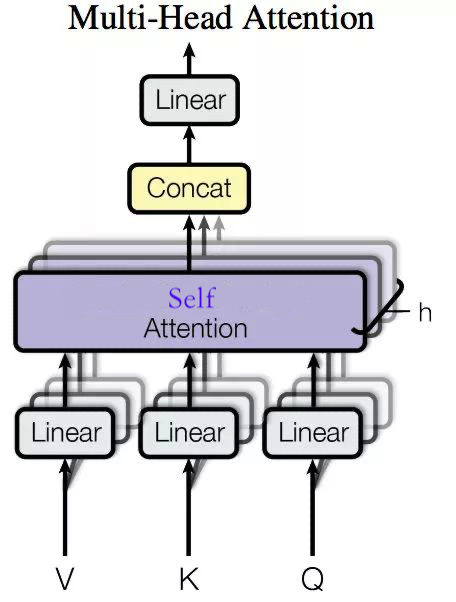
把输入的X分成若干块,每一块分别进行自注意力计算,然后进行统一的线性变换,得到输出Z
从空间的角度理解,就是把数据在空间中的映射,分成若干块进行拟合