笨办法学c,ysyx前置课程
参考资料:Learn C the hard way
实验系统:macos
文本编辑器:Sublime
Exercise 1
int main(int argc, char *argv[])
{
puts("Hello world.");
return 0;
}
在终端中make
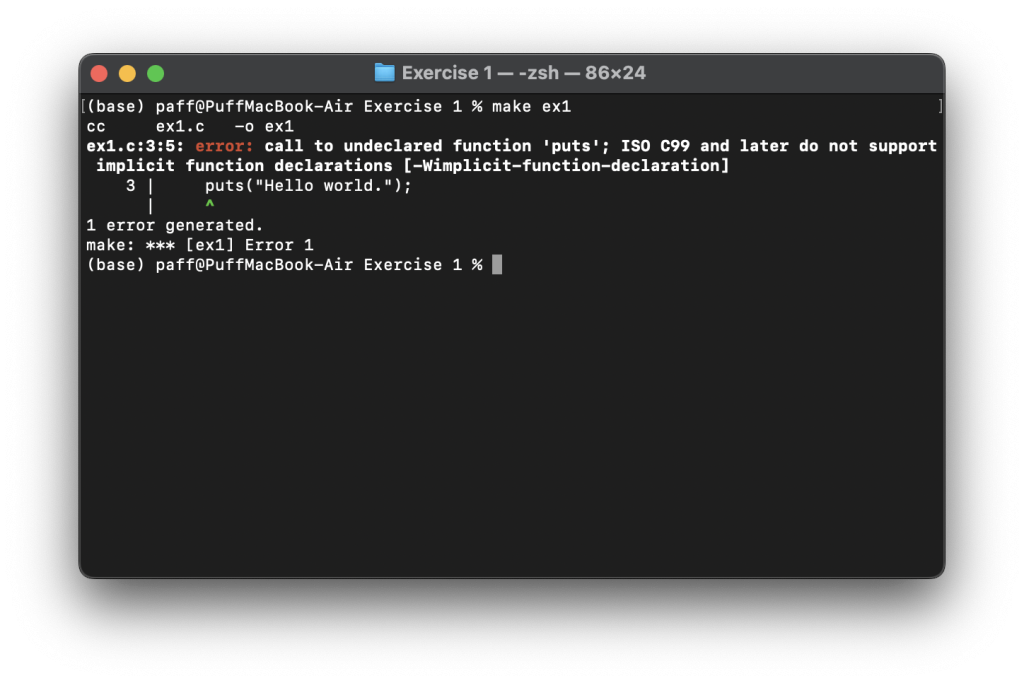
报错,与书中写的似乎不同,无法make
添加编译警告后make
依然如此,问题是缺少头文件,修改代码包含进stdio.h
再次make,成功,生成ex1可执行文件并执行
./ex1
正常输出“Hello world”
附加题
1.删除 return 0 后make,期望得到返回值的warning,结果是没有返回值的warning(即使打开编译器警告),主函数默认返回了0
2.puts函数似乎是自动换行的
3.man 3 puts看一下即可
Exercise 2
主要介绍了Makefile
CFLAGS=-Wall -g
clean:
rm -f ex1
Makefile的内容,
CFLAGS:打开编译warning
clean:快速清理项目
Makefile可作为一个快捷工具,在终端中执行make clean即可删除ex1可执行文件,并且默认开启了编译时warning
在编写Makefile的时候,注意要打开编辑器设置,取消把tab转换成空格的设定,可以只针对某一类文件勾选(例如Makefile),否则其他文件可能会出问题
附加题
1.只使用make就可以编译,借助于all:ex1
原理是make的时候默认会去找第一条make的目标,自然而然就找到了ex1。使用all还有一个好处,就是可以在后面添加多个程序,这样就可以一次性make整个大项目出来。
make ex1的时候,语法指定如下
cc $(CFLAGS) -o ex1 ex1.c
这里CFLAGS是开头定义的编译规则,也可以替换成 -Wall -g,但是这样写有多个目标需要make的时候就不便于管理,因此需要在开头统一定义
ex1:ex1.c监测ex1是不是最新的ex1 make出来的,如果是就make,不是则提示
make: Nothing to be done for `all'.
Makefile如下
CFLAGS=-Wall -g
all:ex1
ex1:ex1.c
cc $(CFLAGS) -o ex1 ex1.c
clean:
rm -f ex1
2 & 3.
man make和man cc看一下既可
4.可加入自动变量来代替ex1,但个人感觉不太直观
5.还没做
Exercise 3
介绍了格式化输出
格式字符串(%d,%f)等,会将变量替换进输出中
如果后面不带变量,编译器会自己指定成随机的
如果不初始化变量,也会制定成随机的
附加题
1.改变量名、改语法错误等
2.man 3 printf 查看即可
3.编写makefile
- 收回Exercise 2 里的认识,自动变量很有用
现在需要同时make项目下的所有文件,假设为ex1,ex2,ex3,同时把他们一起clean掉
clean 简单,直接rm ex1 ex2 ex3即可(空格隔开)
make的时候,为了优雅地写,不给每个c文件单独制定make选项,需要使用通配符%
$@ 代表所有构件目标
$< 代表所有源文件
原理是当all发现通配符下的一个需要构建的文件时候,就将目标和源文件替换
Makefile 如下
CFLAGS=-Wall -g
all:ex1 ex2 ex3
%:%.c
cc $(CFLAGS) -o $@lt; clean: rm -f ex1,ex2,ex3 Exercise 4
介绍了Valgrind工具,用于检查代码错误并报告
本次更换了实验环境,原因是arm架构的mac本不支持Valgrind工具的安装,开了一个虚拟机,之后和Valgrind有关的都用虚拟机解决
但是,由于内核的版本过高了,源码编译要找到合适的版本比较困难,因此还是apt install了,之后有空再用源码编译一下
附加题
1.把未初始化的变量初始化即可
2.
3.
4.大致是这样:coregrind/目录下存放了二进制插桩(DBI)引擎,将机器码转换为IR表示,在此基础上分析代码。VEX/存放了不同架构下的转换库,include/存放了公共头文件与上述各个模块通信之间的API
Exercise 5
介绍了C程序的基本结构
学习过,没有问题
附加题
略
Exercise 6
介绍了变量类型
主要是学过的,%d,%f,%c,%s等
补充:变量名称搭配错误会引起段错误(Segmentation fault),原因是访问了不该访问的内存,导致错误,在搭配错误时因为不同变量所占内存空间不同会导致这个错误
附加题
4.打印空字符串:使用格式化输出即可,%s," "
Exercise 7
介绍了变量的一些规则
在char类型的变量被写入printf表达式时,会自动进行整数提升,转化为ASCII中的int类型
然而%s期望得到一个指向字符串首地址的指针,因此变量类型不匹配,会引发段错误
附加题
1,2.当数字越界时会保存溢出值并打印,依据编译器不同而打印的值不同,不可预知
4.unsigned把有符号数的符号位也用来表示数
5.整数提升,char将字符转化为int,因此可以相乘
Exercise 8
隐晦地介绍了字符串的内容
字符串以\0结尾以让编译器识别字符串的结尾
手动定义字符串时,用这种形式char name[]="Zed"编译器会自动补\0,如果用引号定义一个个字符(例如char name = ["Z","e","d","\0"]),最后要加\0否则会报错,当然在main函数外这么定义可能会成功
附加题
1,2,3.常用的赋值操作,都是合法的,注意字符串的索引,最后一位为空
4.(AI搜集)
8位 CPU (如 Arduino Uno):
int通常是16位 (2字节)。16位 CPU (如 早期DOS系统):
int通常是16位 (2字节)。32位 CPU (如 x86):
int通常是32位 (4字节)。long也通常是32位。64位 CPU (如 x86-64, ARM64):
- 在 Linux 和 macOS 上,通常采用 LP64 模型:
int是32位 (4字节),long是64位 (8字节),指针是64位。 - 在 Windows 上,通常采用 LLP64 模型:
int是32位 (4字节),long也是32位 (4字节),long long是64位 (8字节),指针是64位。
- 在 Linux 和 macOS 上,通常采用 LP64 模型:
Exercise 9
还是字符串
附加题
1.会报错,但是编译器进行整数提升,同时会因为编译器的问题,自动寻址到字符的最低位地址对应的字符输出了
2.不报错,打印字符对应的ASCII码
4.可以,使用指针引用首字符的地址即可,打印出的整数是这四个字符拼在一起得到的
我的代码是这样
char* q = name;
int* p = (int*) q;
printf("%d",*p);
6.题目的意思似乎是要命名一个指针指向“Zed”
可以写一段测试代码
char* another = name;
another[0]="m";
使用Valgrind检查,报了段错误,根本原因是“Zed”这个字符串被加载到了只读的内存区域
但是使用数组时,可以修改内容,这是因为声明数组的内容是在栈中的,可以修改